1. 协程定义
概念:协程就是协同工作的程序,不是进程也不是线程 理解成–不带返回值的函数调用。
Coroutine:协程,又称微线程,纤程。 协程的这种“挂起”和“唤醒”机制实质上是将一个过程切分成了若干个子过程,给了我们一种以扁平的方式来使用事件回调模型。优点:共享进程的上下文,一个进程可以创建百万,千万的coroutine。 python中的yield和第三方库greenlet,都可以实现协程。 greenlet 提供了在协程中直接切换控制权的方式,比生成器(yield)更加灵活、简洁。
GIL–限制了python的多线程
即时通讯服务器 + 协程方式运行,提供并发性
服务器: 多进程 多线程 协程
Flask(框架)+Gunicorn(服务器)+(协程)高并发的解决方法探究
使用Flask的做服务器框架,可以: python code.py 的方式运行,但这种方式不能用于生产环境,不稳定,比如说: 有一定概率遇到连接超时无返回的情况—flask提供的简易测试服务器
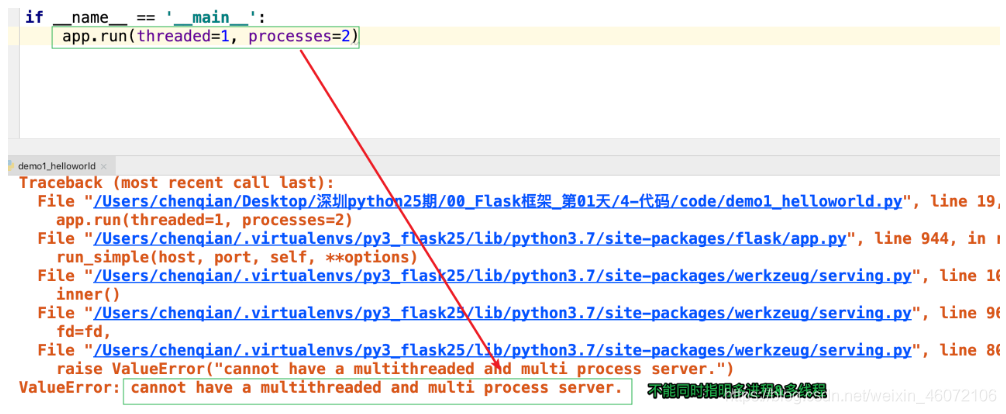
1,通过设置app.run()的参数,来达到多进程的效果。看一下app.run的具体参数:

注意: threaded与processes不能同时打开,如果同时设置的话,将会出现以下的错误:
2. 解决方案
2.1 方案一
使用gevent做协程,从而解决高并发的问题:
Flask + gevent
# 携程的第三方包-这里选择gevent, 当然你也可以选择eventlet
pip install gevent
# 具体的代码如下:
from flask import Flask
from gevent.pywsgi import WSGIServer
from gevent import monkey
# 将python标准的io方法,都替换成gevent中同名的方法,遇到io阻塞gevent自动进行协程切换
monkey.patch_all()
# 1.创建项目应用对象app
app = Flask(__name__)
# 2.初始化服务器
WSGIServer(("127.0.0.1", 5000), app).serve_forever()
# 启动服务---这样就是以协程的方式运行项目,提高并发能力
python code.py
通过Gunicorn(with gevent)的形式对app进行包装,从而来启动服务【推荐】
Falsk + Gunicorn + gevent
安装遵循了WSGI协议的gunicorn服务器–俗称:绿色独角兽
pip install gunicorn
查看命令行选项: 安装gunicorn成功后,通过命令行的方式可以查看gunicorn的使用信息。
$ gunicorn -h

指定进程和端口号: -w: 表示进程(worker) --bind:表示绑定ip地址和端口号(bind) —threads 多线程 -k 异步方案
# 使用gevent做异步(默认worker是同步的) 多进程+协程 gunicorn -w 8 --bind 0.0.0.0:8000 -k 'gevent' 运行文件名称:Flask程序实例名 # 使用gunicorn命令启动flask项目 # -w 8 8个进程 # --bind 0.0.0.0:8000 ip + 端口 # -k 'gevent' 协程
方案二
将运行的信息加载到配置文件中
使用gunicorn + gevent 开启高并发
新建配置py文件:gunicorn_config.py
# 多进程 import multiprocessing """gunicorn+gevent 的配置文件""" # 预加载资源 preload_app = True # 绑定 ip + 端口 bind = "0.0.0.0:5000" # 进程数 = cup数量 * 2 + 1 workers = multiprocessing.cpu_count() * 2 + 1 # 线程数 = cup数量 * 2 threads = multiprocessing.cpu_count() * 2 # 等待队列最大长度,超过这个长度的链接将被拒绝连接 backlog = 2048 # 工作模式--协程 worker_class = "gevent" # 最大客户客户端并发数量,对使用线程和协程的worker的工作有影响 # 服务器配置设置的值 1200:中小型项目 上万并发: 中大型 # 服务器硬件:宽带+数据库+内存 # 服务器的架构:集群 主从 worker_connections = 1200 # 进程名称 proc_name = 'gunicorn.pid' # 进程pid记录文件 pidfile = 'app_run.log' # 日志等级 loglevel = 'debug' # 日志文件名 logfile = 'debug.log' # 访问记录 accesslog = 'access.log' # 访问记录格式 access_log_format = '%(h)s %(t)s %(U)s %(q)s'
执行:
gunicorn -c gunicorn_config.py flask_server:app
方案三
使用 meinheld + gunicorn + flask 开启高并发神器
前提在虚拟环境中安装meinheld:
pip install meinheld
import multiprocessing """gunicorn+meinheld 的配置文件""" # 预加载资源 preload_app = True # 绑定 bind = "0.0.0.0:5000" # 进程数: cup数量 * 2 + 1 workers = multiprocessing.cpu_count() * 2 + 1 # 线程数 cup数量 * 2 threads = multiprocessing.cpu_count() * 2 # 等待队列最大长度,超过这个长度的链接将被拒绝连接 backlog = 2048 # 工作模式 worker_class = "egg:meinheld#gunicorn_worker" # 最大客户客户端并发数量,对使用线程和协程的worker的工作有影响 worker_connections = 1200 # 进程名称 proc_name = 'gunicorn.pid' # 进程pid记录文件 pidfile = 'app_run.log' # 日志等级 loglevel = 'debug' # 日志文件名 logfile = 'debug.log' # 访问记录 accesslog = 'access.log' # 访问记录格式 access_log_format = '%(h)s %(t)s %(U)s %(q)s'
# 运行方式 命令行
gunicorn -c gunicorn_config.py flask_server:app
2. 历史遗留问题—GIL锁
2.1 简介
1.线程安全是在多线程的环境下,线程安全能够保证多个线程同时执行时程序依旧运行正确,而且要保证对于共享的数据,可以由多个线程存取,但是同一时刻只能有一个线程进行存取。每一个interpreter进程,只能同时仅有一个线程来执行,获得相关的锁,存取相关的资源。那么很容易就会发现,如果一个interpreter进程只能有一个线程来执行,多线程的并发则成为不可能,即使这几个线程之间不存在资源的竞争。 2.所以虽然 CPython的线程库直接封装操作系统的原生线程,但CPython进程做为一个整体同一时间只会有一个获得了GIL的线程在跑,其它的线程都处于等待状态等着 GIL的释放。所以只能使用cpu单核。这也是python多线程被人诟病的原因。
2.2 解决方案
python的高并发更加推荐多进程+协程
io多路复用
IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,它就通知该进程。 1. select(线程不安全):它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作。 2. poll(线程不安全):它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制 3. epoll(线程安全):epoll可以同时支持水平触发和边缘触发 Level_triggered(水平触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait()时,它还会通知你在上没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你!!!如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率!!! Edge_triggered(边缘触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符!!! 阻塞IO:当你去读一个阻塞的文件描述符时,如果在该文件描述符上没有数据可读,那么它会一直阻塞(通俗一点就是一直卡在调用函数那里),直到有数据可读。当你去写一个阻塞的文件描述符时,如果在该文件描述符上没有空间(通常是缓冲区)可写,那么它会一直阻塞,直到有空间可写。以上的读和写我们统一指在某个文件描述符进行的操作,不单单指真正的读数据,写数据,还包括接收连接accept(),发起连接connect()等操作... 非阻塞IO:当你去读写一个非阻塞的文件描述符时,不管可不可以读写,它都会立即返回,返回成功说明读写操作完成了,返回失败会设置相应errno状态码,根据这个errno可以进一步执行其他处理。它不会像阻塞IO那样,卡在那里不动!!!
python异步实现
多进程 + 协程 + callback(io多路复用做事件驱动)
3. 协程 第三方封装库:
gevent = greenlet + python.monkey(底层使用 libevent 时间复杂度: O(N * logN))
meinheld = greenlet + picoev (时间复杂度: O(N) )
eventlet
picoev和libevent
meinheld和gevent都能实现异步,但是测评中meinheld比gevent的性能好很多,不过因为meinheld支持的比较少,一般都是配合gunicorn使用的。下面分析一下meinheld和gevent性能差距主要原因,分别使用的是picoev和lievent。 # libevent 主要实现:使用堆(优先队列)作为timer事件的算法(nlogn),IO和信号的实现均使用了双向队列(用链表实现)。 时间复杂度: O(N * logN) # picoev picoev主要优化有两点。 1. 主要是考虑是fd(file descriptors)在unix中是用比较小的正整数表示的,那么把fd的相关信息,全部存储在一个array中,这样使得查找快速,在操作socket状态时会更加的快。 2. 第二点是对于timer事件的算法优化,通过环形缓冲区(128)和bit vector实现查看部分源码可以看出,主要实现是每个时间点对应的是缓冲区的一个位置,每个缓存区使用bit vector 表示fd的数值,相当于一种hash映射所以时间复杂度为(o(n)),n为那个缓存区所存的fd数量。 时间复杂度: O(N) 性能: picoev > libevent
理解----协程&线程&进程
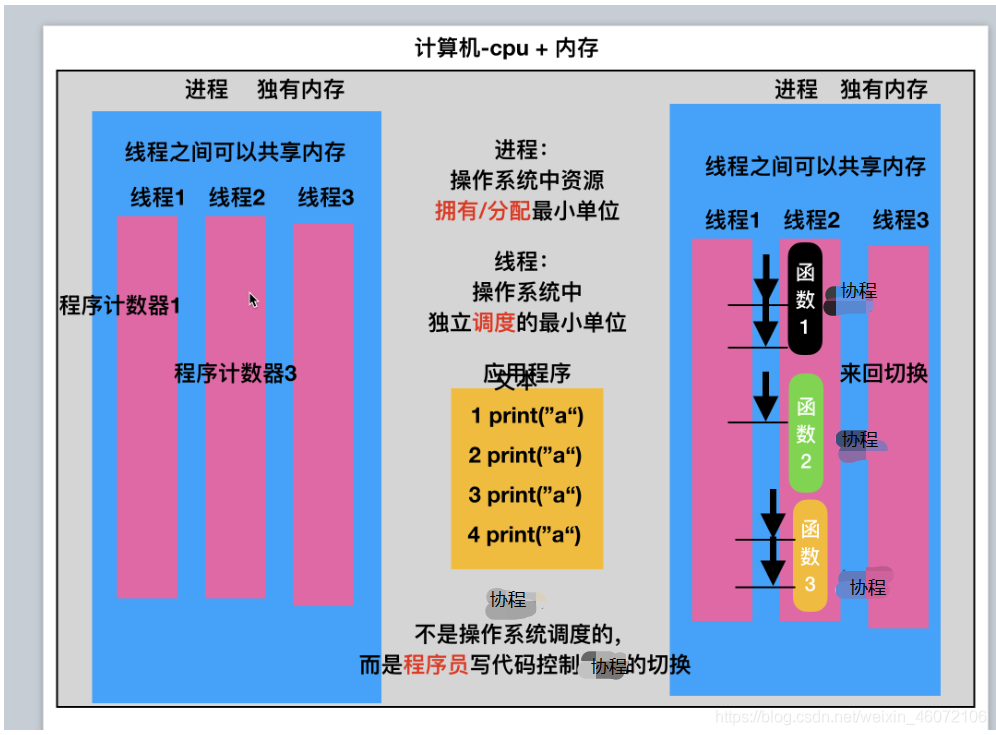
2.思考:协程之前切换的场景?
程序发送阻塞的时候切换
读磁盘
读写文件
网络io操作
收发http请求