大家可能都知道BT是基于点对点,也就是P2P的技术原理,但是细节可能并不是很清楚了。
张3下载到了一个BT种子,加载到了BT客户端里,BT客户端根据种子得到了这个种子的唯一标识,也就是HASH码。BT客户端连接到了DHT网络之后,知道了李4和王5也加入到了DHT网络中,于是张3(的BT客户端)就向李4和王5问,你看看我的这个HASH码,你们有它的数据吗。如果得到肯定的答复,就开始在他们的电脑上下载这个种子的文件,如果李4和王5也没有下载完这个种子的文件,那么他们之间则是互相下载没有完成的数据。DHT网络里还有更多的赵6和孙7们,它们每个人负责维护一个很小的关系网,通过这些关系网交织起来,就形成了一个完整的DHT网络,和现实中的人际关系网络很相似。
基于上面的原理,本文中提供的代码就是伪装成李4或者王5,等很多的张三们上门询问HASH码,然后记录下HASH,不需要下载对应的种子中的文件,当然也更没有文件可以上传,只是为了获取HASH。
但是有了HASH还不够,HASH本身并不包含任何信息,它只是为了和一个BT种子对应上,所以有了HASH之后还得拿着它去获取种子,怎么获取?比如我们得到了这个HASH,73443840827B2D25B659D6825521D37DCA8F09B8,那么,看下面的URL:
https://torcache.net/torrent/73443840827B2D25B659D6825521D37DCA8F09B8.torrent
通过这个URL,我们可以把种子下载回来。并不是所有的HASH都可以在torcache这个站上下载到,也并不是只有torcache这一个站可以下载种子,所以,为了尽可能高几率的获取到种子,需要加入更多存放种子的站。
通过这个种子,我们可以知道更多的信息了,主要是知道了种子里的文件信息,如下图:
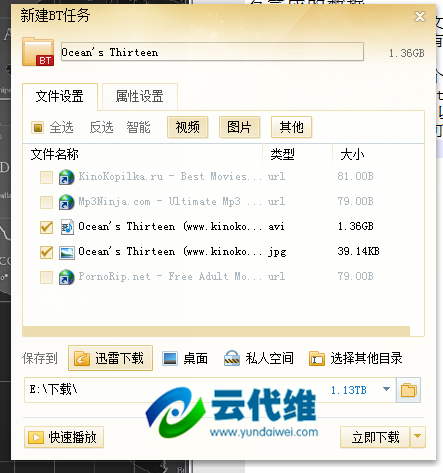
这是在迅雷中看到的,用PHP和Python脚本都可以得到这些信息,网上有公开的代码,请自行下载。再强调下,必须得到种子才能得到这些文件信息,如果只知道HASH码,没有办法根据HASH码直接得到它的里面包含的文件的信息。
torcache这个站只是为了演示之用,等你看到这篇文件的时候,这个站有可能已经失效了(虽然可能性很小)。
下面开始介绍如何运行附件中的演示代码(代码来源于网络,并非本人所写)。
首先安装setuptools这个工具。
Debian/Ubuntu中运行命令:
apt-get install -y python-setuptools
CentOS中运行命令:
wget -q http://peak.telecommunity.com/dist/ez_setup.py
python ez_setup.py
解压附件,可以看到其中有一个bencode目录,进入之后,执行
python setup.py install
注,bencode来自这个地址,https://github.com/bittorrent/bencode。
上面的步骤完成之后,就可以开始抓HASH了。
抓取种子的代码建议根据自己的规划自行编写。解析种子以及其他相关的代码可以到github上搜索,非常多,不得不感慨,开源世界很美好。
附件中的代码不是很完善,比如多线程和数据库的部分。
想继续深入研究的也可以看看这个链接,https://github.com/0x0d/dhtfck。
标题中的1亿并不是噱头,实际能抓取到的数量肯定会超过1亿。
平均一个种子按20Kb计算,1亿个种子,需要2TB的存储空间。
建议下载到种子后,只保存一些关键信息,比如种子名称,里面的文件信息,然后只提供磁力链接,这样需要的存储空间会小一些,但是仍需要几百GB的空间。
对于上亿数据量的网站的构建,抓取到种子,仅仅是一个开始。
另外,这种网站在版权,XX信息等方面,都成问题,并不建议大家真的去做成网站,请考虑清楚后果,本文本意仅提供技术研究之用。
http://pan.baidu.com/s/1dDiymhr